“Data cooking”: The Process For Making Artichoke Dips
Gitika Gorthi, Chantilly High School
Food and data are quite similar. How come? Let me explain. Both are consumed for the purpose of nourishment. In case of food, it is our body and in case of data, it is the model that we are trying to build.
Whether it be by using a blender or our teeth, we process all of our food before consumption to avoid choking. To be more specific, imagine eating an artichoke. Will you just consume it at once or will you process it with your teeth before consumption? Most of us will do the latter to avoid choking by the extremely nutritious vegetable. The same conceptual idea is applied on data. Data is powerful and imperative for technological advancements; however, if raw data is fed into machine learning (ML), Fast Fourier Transform (FFT), or other similar systems without the cooking or cleaning parts, it may lead to dangerous outcomes instead.

Figure 1: Labeled illustration of the good and choke parts of the artichoke.
Daily on the news, we read about remarkable technological advancements that once seemed like science fiction -- such as self-driving cars. Nonetheless, companies such as Tesla have made many Hollywood writers’ stories a reality. According to Andrej Karpathy (Tesla’s head of artificial intelligence and computer vision), in February 2020 Tesla cars have driven 3 billion miles on Autopilot. Tesla software developers were able to make self-driving a reality by working with various processing tools. However, what if all the data they work with is not “cooked” properly? You guessed it, the end product would not be “tasty”.
A recent example of this in the May article “Tesla in deadly California crash was on Autopilot” where a 35-year-old man was killed when his Tesla Model 3 struck an overturned semi-truck on a freeway at about 2:30am when it was on autopilot (self-driving mode). Situations like that illustrate the necessity to fully process data, as it could be saving a few hundred lives annually out there. Now that we have a deeper understanding on the importance of data processing, let’s discuss specific tools.
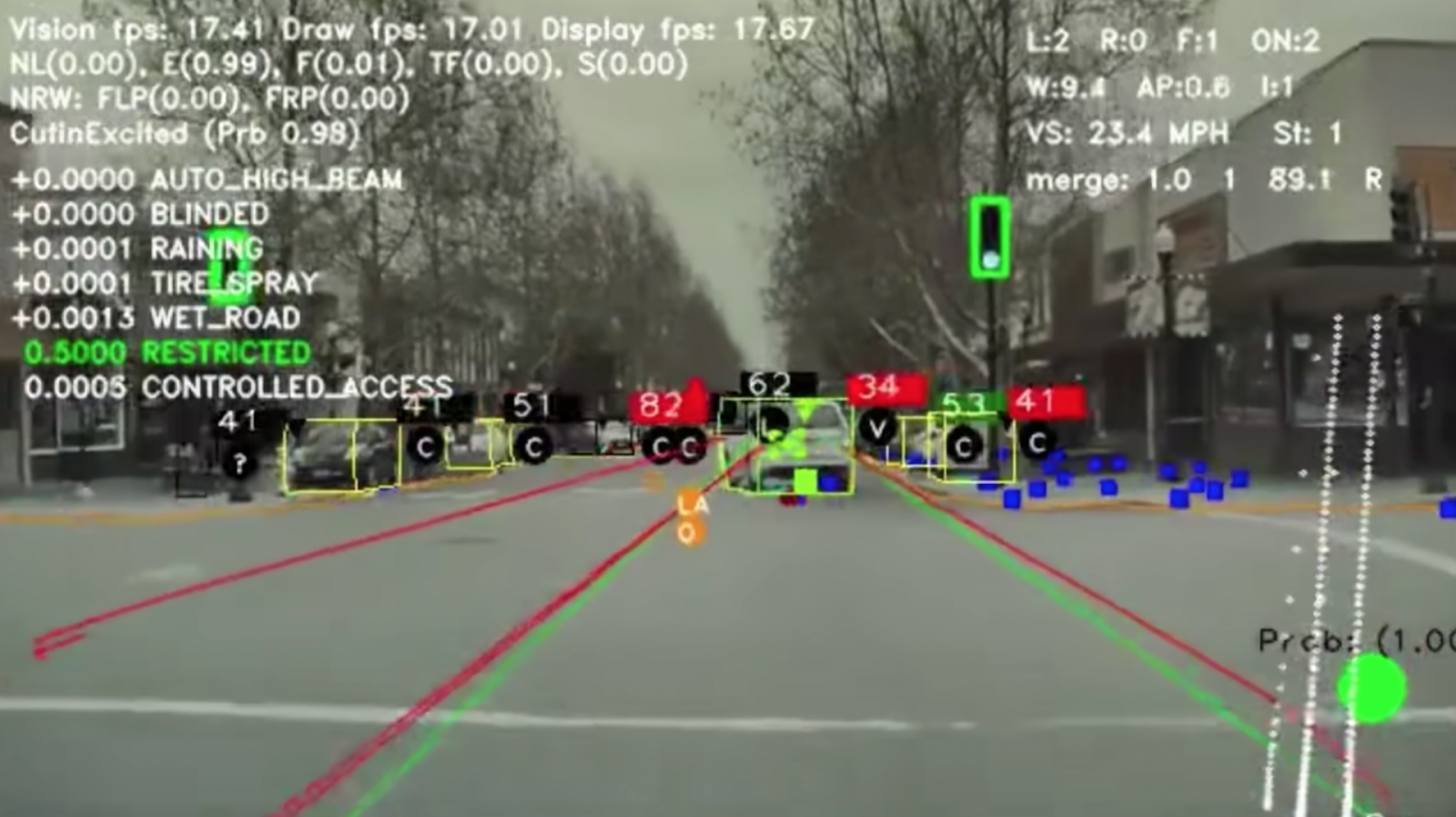
Figure 2: The image above represents what the Tesla Autopilot sees. If anything is miscalculated or misprocessed, it could be fatal to drivers.
There are many data processing tools, but let’s talk specifically about the image processing tool the FFT as it has a wide range of applications. FFT is a processing tool used to “decompose an image into its sine and cosine components”, where it can be used for “image analysis, image filtering, image reconstruction, and image compression” (A. Marion, 1991).

Figure 3: The above image is a “Butterfly Diagram” & it represents the FFT algorithm as a visual diagram.
The FFT can be used in the healthcare industry by allowing for more precise diagnosis with the aid of medical devices. For those who may be unaware, medical image processing is rapidly growing in the healthcare world. From the non-invasive exploration of 3D image datasets of the human body using Computer Tomography (CT) or Magnetic Resonance Imaging (MRI) Scanners for surgical planning to diagnosis of pathologies to advance research, data image processing is proving to be critical in a hospital’s success (Synopsys, 2021).
Additionally, the FFT can be used in various smart tools, such as thermostats -- devices that are used to sense and regulate the temperature of the air, liquids, or other processes. Many of the newly developed thermostats incorporate advanced machine learning algorithms to adapt to user preference and schedule. To provide a more specific example, new smart WiFi thermostats using a regression tree approach (Random Forest) to develop models to predict the room temperature as measured by each thermostat and the cooling status (Huang et al, 2018).
Like self-driving cars, medical devices, and thermostats, there are many tools in this digital era that run on accurate data processing. The next time you are chewing on some artichoke dips, remember the importance of processing data as efficiently as them.
Comments
Post a Comment